・
俗・"デベロッパーキャンプ、ご参加ありがとうございました。" を検証する。
2/29 の雑談の続きです。資料を検証してみました。
David.I が "SizeOf (Char) は Sizeof (Byte) と同等ではなくなる" の話の中で、Unicode をして 「1 バイトから 4 バイト」 と言っていましたが、これは誤りです。プレゼン資料の P.7 にある、"Unicode Support" の図のイメージが頭にあるのでしょうか?これは UTF-8 の概念です。Tiburón のコードエディタは恐らく UTF-8 がデフォルトですから、これと混同しているのかもしれません。
コードエディタが Unicode (UTF-16)ではなく UTF-8 なのは幾つかの理由があると思います。
ini / inf / reg ファイルの扱い
これらは Unicode (UTF-16)を許容します。多言語対応ドライバファイルの中にある *.inf は殆どが Unicode で記述されています。ネイティブアプリにはこちらの方が縁が深いハズなのですが...。
オーバーヘッド
当然ながら UTF-8 -> UTF-16 への変換時にオーバーヘッドが存在します。僅かばかりでしょうが、コンパイル速度の低下に繋がると思われます。加えて言うなら、ANSI / UTF-8 は ASCII の範囲において互換性がありますので、"ソースコードがどちらのエンコーディングなのか?" を調べる必要があります。BOM 付き UTF-8 なので、容易に区別は付きますが。
BOM 付き UTF-8
本来、UTF-8 には BOM は存在しません。BOM とは "Byte Order Mark" の事で、WORD 単位で文字を処理する場合に使われます。UCS-2 や UTF-16 が "WORD 単位処理" です。UCS-2 / UTF-16 等は、1 文字の単位が WORD の倍数なので、1Byte 単位で処理するのではなく、1WORD 単位で処理すると効率的です。
ところが、処理系によってはハイバイトとローバイトが入れ替わる場合があります。"0x1234"という WORD のデータを読む場合、"0x12 0x34" と表現されるのがビッグエンディアン、逆に "0x34 0x12" となるのがリトルエンディアンです。このエンディアンを識別する為に UTF-16 では 0xFEFF (ビッグエンディアン) / 0xFFFE (リトルエンディアン)をファイルの先頭に付加します。
UTF-8 は先に述べたように "Byte 単位処理" なので、エンディアンは関係ありません。では何故 UTF-8 に BOM があるのでしょうか?それは "ASCII と区別が付かない事があるから"です。"ASCII 圏の人には最小限の変更で済むアップグレードパス" ではありますが、ASCII の範囲で書かれたテキストファイルは、それが ASCII なのか UTF-8 なのか区別が付きません。例え ASCII の範囲以外の文字があっても容易に判断できるものではなく、文字化けの原因となります。これを回避するために UTF-8 に BOM を付加する必要があったのです。
しかしながら、この BOM 付き UTF-8 は "本来は規格外" であるため、処理系によっては異常をきたす場合があります。"Delphi for PHP" に於いてもこの問題が影響する事があるようです。詳しくは "BOM 付き UTF-8 と include/require の問題? (Delphi for PHP の使い方)" を参照して下さい。
・
これだけでは面白くないので、コードエディタの話をしましょう。
QC#10711 の問題は依然として先送りになっていますが、この問題は Tiburón でも直りそうにありません。ガリレオ IDE のコードエディタは先に述べたように UTF-8 をサポートしています。新規でテキストファイルを作成し、"Tibuurón" と入力して保存すると UTF-8 で保存されます。この UTF-8 で保存されたファイルで日本語を含んだ矩形選択を行うと、やはり矩形領域は不正になってしまいます。
「Unicode になったら解決するから先送りしよう」...この判断は間違っています。何故なら、Unicode の表現方法とフォントの幅にはなんら因果関係がないからです。現行の IDE で解決できなければ、Tiburón でも解決できません。断言します。逆に Tiburón で解決できるのなら、現行の IDE にもフィードバックできるという事です。
"2 バイト半角文字" というものがあります。これは 2 バイトで表わされる文字なのに、大きさ自体は 1 バイトで表わされる文字と同様、というものです。他にも、Unicode には結合文字列という厄介なものもあります ("Vista で化ける字,化けない字(続報)"参照)。ほーら、頭が痛くなってきたでしょう?
"𠀋" (丈の右上に点) という文字はサロゲートペアの文字です (環境によっては読めないかもしれませんが、ご了承下さい)。IDE で新規でテキストファイルを作成し、この文字をひたすら入力 (或いはこのページからコピペ) します。そして、文字を矩形ではなく普通に選択すると...選択文字が消える事があります。そして、このテストではっきりした事があります。
・
矩形選択バグの真相
Delphi 2007 の IDE で新規でテキストファイルを作成し、以下のような文字を入力します ("4" の下の文字が□に見える方へ。□の部分は "丈の右上に点" なサロゲートペアです)。
|
これを矩形選択してみます。
・
ヘルプアップデート #2
またもや地道に良くなって来てはいますね。どうやら、Doc-O-Matic での修正に拘りがあるようですね。彼女がその道を選んだのであれば否定するつもりはありませんが、"パッケージ製品" に於いては、生成過程よりも成果物の出来が重要視される事を忘れている訳ではないですよね?
私は 「ユーザは成果物の品質を求めているのだから、プリプロセッサ / ポストプロセッサを構築してでも修正すべき」 と主張しました。ですが、"Doc-O-Matic への拘り" は長期的な目で見れば Doc-O-Matic の製品としての品質向上と、その成果物の品質向上の双方に於いてメリットが大きいでしょう。確かに一時的なプリプロセッサ / ポストプロセッサは後々の事を考えれば "無駄な作業" ではありますし。
...ただ、私もリバースエンジニアリングをしてまで Help を精査する事は今後一切ないと思います。"Doc-O-Matic の品質向上 (それに伴い成果物の品質も向上する)" が選んだ道なのであれば、リバースエンジニアリングを伴う Help の精査は "無駄な作業" という事がハッキリしているからです。お手並み拝見、といきますか>Dee Elling。
・
何故、最近こんな記事ばっかりなのか?
今月中旬には始まると思われる Tiburón の FT に参加したら書きたい事も書けなくなるからです (NDA の縛りによって)。憶測だろうが推測だろうが、書けるうちに問題点は書いておきます。書いたトコロは FT で重点的にツッコミを入れる箇所だと思って下さって結構です。その代わり、FT に突入したら、自分が書いた記事についての真偽を問われても肯定も否定もしませんし、記事の訂正も行いません (少なくとも製品がリリースされるまでは)。
重要であると思われる Unicode 絡みの話は、恐らく FT 専用 NG でしか議論できません。Tiburón の FT へ一名でも多くの参加がある事を切に願っています。特に BCB 使いの方の参加は急務です。BCB の Unicode は Delphi のそれに比べて遥かに厄介です。"Unicode に対する情報を得る" / "議論の内容を知る" ためだけでも構わないので、FT への参加をお願いします。
・
深淵なる Unicode
「文字ばかりでイメージが湧かない」 と仰る方のために、図解付きでおさらいしたいと思います。
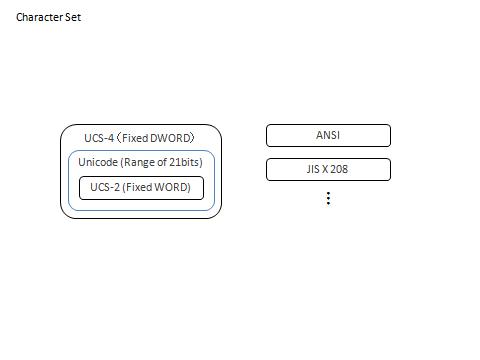
[Character Set / キャラクタセット / 文字セット / 文字集合]
名前の通り、文字の集合です。"ANSI"は英数記号の文字集合、"JIS X 208"は日本語の文字集合、"Unicode"は全世界で使われる文字の集合です。
UCS-2 も UCS-4 も文字集合ですが、Unicode ではありません。Unicode とは別の文字集合です。但し、Unicode とは互換性があります。
[Encoding / キャラクタエンコーディング / 文字エンコーディング / 文字符号化方式]
文字エンコーディングは、広義の文字集合ですが、正確には "文字集合を符号化して用途に合わせたもの" です。
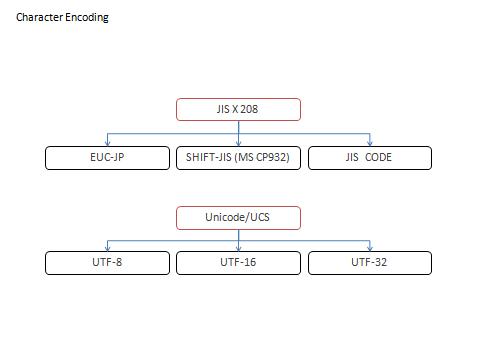
"JIS X 208" を符号化して ANSI と共存できるようにしたものが、Shift_JIS / EUC-JP / JIS CODE です。これらは ANSI を 1 バイト (7 bit)、日本語を 2 バイトで表現します。同様に、"Unicode" や "UCS-2 / UCS-4" を符号化したものが、UTF-8 / UTF-16 / UTF-32 です。中には "文字集合=文字エンコーディング" になっているものもあります。これらは "無符号化文字集合" と考える事ができます。
[Shift_JIS (MS CP932)]
ANSI と互換性のある日本語エンコーディングの一種です。Windows では CP932 というコードページが与えられています。

7bit 分を ANSI に割り当てそのまま 1 バイトで表現、残りの領域を拡張領域に使って 2 バイトで日本語 (JIS X 208) を表現します。2 バイト文字の 1 バイト目は 0x81-0x9F / 0xE0-0xFC、2 バイト目は 0x40-0x7E / 0x80-0xFC で表現されます。これにより 11,280 文字を 2 バイト文字で表わす事ができます。
2 バイト文字の 1 バイト目と 2 バイト目に重複した領域があり、さらに 2 バイト文字の 2 バイト目は ANSI 領域と重複しているため、以下のような問題が発生します。
[UTF-32]
Unicode / UCS を DWORD (32bit) で処理するように符号化したものです。
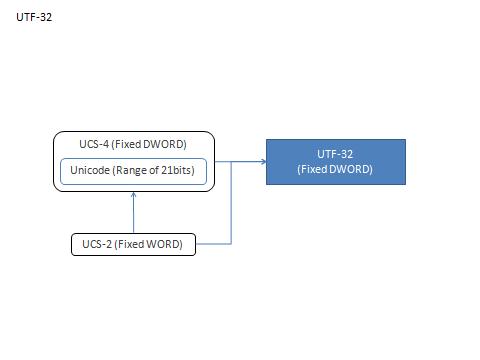
UCS-2 からは単純に WORD -> DWORD へアップスケールしてやるだけ (但し、UCS-2 の範囲外の文字は表現できません)、Unicode / UCS-4 なら無符号化でイケます。すべての文字をリニアに扱う事が可能です。最もシンプルに Unicode を扱う方法ですが、データサイズの肥大化は避けられません (詳しくは後述します)。
[UTF-16]
Unicode / UCS を WORD (16bit) で処理するように符号化したものです。
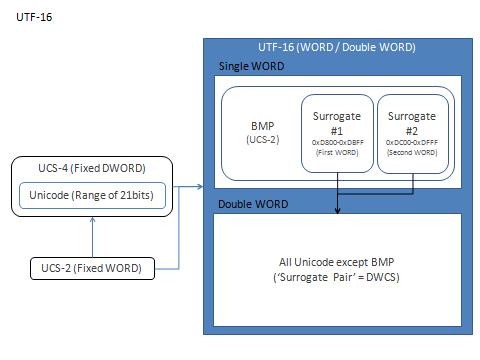
本来は、Unicode をリニアに扱うための符号化方式でした。Unicode が 16bit の範囲にあった頃はすべての文字をリニアに扱う事が可能でしたが、Unicode が 16bit の範囲を超えてから、これを扱えるようにすべく Shift_JIS によく似た拡張が行われました。1 WORD で表わされる領域は UCS-2 と互換性があります。拡張に使われる領域 (サロゲート)が 1 WORD 目と 2 WORD 目で重複せず、BMP とも重複しないため Shift_JIS のような問題は発生しません。
[UTF-8]
Unicode/UCS を byte(8bit)で処理するように符号化したものです。

1 バイトで表わされる文字は ANSI 互換です。1 バイト文字の一部の領域を拡張領域に使って 2 バイト文字を表し、さらに 2 バイト文字の一部の領域を拡張領域に使って 3 バイト文字を表す...という事を繰り返してすべての Unicode / UCS 文字を表現します。最大で 1 文字は 4 バイトになります。何故なら、4 バイトで Unicode の範囲( 21bit )をカバーできるからです。但し、UCS-4 の範囲をすべてカバーするには 5 バイト文字、6 バイト文字が必要です。
UTF-8 も、UTF-16 同様、"Shift_JIS で起こる問題" は発生しません。
1 ~ 3 バイト文字は Unicode の BMP (16bit の範囲内で表わされる Unicode 文字 = UCS-2) を表します。4 バイト文字は BMP 以外のすべての Unicode 文字を表します。また、UCS-2 -> UTF-8 変換では、4 バイト文字は表現できません (最大 3 バイト文字)。
[Unicode]
改めて、Unicode です。
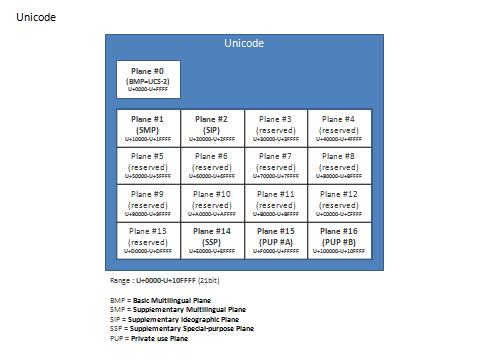
Unicode の範囲は 21bit で U+0000 ~ U+10FFFF の範囲にあります。Unicode を表す場合にはプレフィクスとして "U+" を付ける事になっています。そして U+xxxx で示される文字の格納位置を "コードポイント" と呼びます。U+xxxx で表わされる値そのものはスカラー値と呼びます。
Unicode の先頭 128 文字 (U+0000 ~ U+007F) は ANSI (0x00 ~ 0x7F) をアップスケールしたものと同義です。
現在の Unicode は面 (プレーン) と呼ばれるエリアで管理されています (16bit セグメントのようなものです)。プレーン #0 (第 0 面) は BMP と呼ばれるエリアで、16bit の範囲で収まっていた頃の Unicode と同義です。BMP は UCS-2 と互換性がありますが、当然ながら UCS-2 からの変換ではプレーン #1 ~#16 の領域にある文字を表現できません。
プレーン #1 ~#16 は 16bit の範囲外です。UTF-16 で言う "サロゲートペア"、UTF-8 の "4 バイト文字" がこれに相当します。
| Charset / Encoding | U+0000 ~ U+FFFF | U+10000 ~ U+10FFFF |
| Unicode | BMP (プレーン #0) | プレーン #1 ~ #16 |
| UCS-4 | 0x00000000 ~ 0x0000FFFF | 0x00010000 ~ 0x7FFFFFFF (0x0010FFFF) |
| UCS-2 | 0x0000 ~ 0xFFFF (BMP) | - |
| UTF-32 | 0x00000000 ~ 0x0000FFFF | 0x00010000 ~ 0x7FFFFFFF (0x0010FFFF) |
| UTF-16 | BMP (1 ワード文字) | サロゲートペア (2 ワード文字) |
| UTF-8 | 1 バイト~ 3 バイト文字 | 4 バイト文字 |
Unicode は現在 21bit の範囲にありますが、今後この範囲を超える事があるのでしょうか?プレーン#17 (U+110000 ~ U+11FFFF) は追加されないのでしょうか? UTF-8 で 5 バイト文字 / 6 バイト文字はないのでしょうか?答えは "恐らく No"です。21bit の範囲を超えた場合には、UTF-16 に更なる複雑な拡張、或いは仕様変更が起きるからです。
UTF-16 は Unicode の BMP 以外(サロゲートペア)を 2 WORD で表現します。
| 16 | 15 | 14 | 13 | 12 | 11 | 10 | 9 | 8 | 7 | 6 | 5 | 4 | 3 | 2 | 1 |
| サロゲート #1 (110110) | プレーン番号 (Unicode の上位 5bit) - 1 | Unicode の上位 6bit 目から 6bit | |||||||||||||
| 16 | 15 | 14 | 13 | 12 | 11 | 10 | 9 | 8 | 7 | 6 | 5 | 4 | 3 | 2 | 1 |
| サロゲート #2 (110111) | Unicode の下位 10bit | ||||||||||||||
第 1 ワードに "プレーン番号 - 1" というものがあります。プレーンは #16 までなので、-1 してやれば 4bit で表わせますね...アレ?UTF-16 は #16 プレーンまでしか想定していないのです。プレーン番号を 4bit で表現していますから、UTF-16 ではそのままだとプレーン #17 以降が使えないのです。
"鶏が先か?卵が先か?" になりますが、
今回用意した画像はガイジンサンにも理解できるように "Strange English" で記述してあります(^^;A。素材として PowerPoint 形式のファイルを用意しましたので、適宜修正してお使い下さい。今回の記事でイメージが湧いた方は 2 月の雑談 及び 03/03 の雑談 を読み返すと、Windows / Delphi に於ける Unicode の現状と問題点がハッキリすると思います。
追伸:
2 月の雑談 で Delphi の WideStringToUCS4String() の実装の事を "眉唾" だと言いました。WideString では、"String で Shift_JIS を扱うような要領" で UTF-16 を扱えるハズです (理屈の上では)。UTF-16 文字列を WideString に格納して、WideStringToUCS4String() で UCS4String へ変換すると何が起きるでしょうか? WideStringToUCS4String() 関数は System.pas 内にありますので、答えはご自分の目でお確かめください。
・
UTF-8
昨日の雑談には関係なかったのであえて端折っていた UTF-8 の構造をやりたいと思います。
| 8 | 7 | 6 | 5 | 4 | 3 | 2 | 1 |
| 0 | U+0000 ~ U+007F (BMP) | ||||||
| 8 | 7 | 6 | 5 | 4 | 3 | 2 | 1 |
| 1 | 1 | 0 | U+0080 ~ U+07FF (BMP) の上位 5 ビット分 | ||||
| 8 | 7 | 6 | 5 | 4 | 3 | 2 | 1 |
| 1 | 0 | U+0080 ~ U+07FF (BMP) の下位 6 ビット分 | |||||
| 8 | 7 | 6 | 5 | 4 | 3 | 2 | 1 |
| 1 | 1 | 1 | 0 | U+0800 ~ U+FFFF (BMP) の上位 4 ビット分 | |||
| 8 | 7 | 6 | 5 | 4 | 3 | 2 | 1 |
| 1 | 0 | U+0800 ~ U+FFFF (BMP) の上位 5 ビットから 6 ビット分 | |||||
| 8 | 7 | 6 | 5 | 4 | 3 | 2 | 1 |
| 1 | 0 | U+0800 ~ U+FFFF (BMP) の下位 6 ビット分 | |||||
| 8 | 7 | 6 | 5 | 4 | 3 | 2 | 1 |
| 1 | 1 | 1 | 1 | 0 | U+10000 ~ U+10FFFF の上位 3 ビット分 | ||
| 8 | 7 | 6 | 5 | 4 | 3 | 2 | 1 |
| 1 | 0 | U+10000 ~ U+10FFFF の上位 4 ビット目から 6 ビット分 | |||||
| 8 | 7 | 6 | 5 | 4 | 3 | 2 | 1 |
| 1 | 0 | U+10000 ~ U+10FFFF の上位 10 ビット目から 6 ビット分 | |||||
| 8 | 7 | 6 | 5 | 4 | 3 | 2 | 1 |
| 1 | 0 | U+10000 ~ U+10FFFF の下位 6 ビット分 | |||||
こうなります。
あと 2 ビット分符号化できますので、これを使えば 5 バイト文字 / 6 バイト文字が表現できます (最初のバイトをすべて符号化に使うのであれば 7 バイト文字も可能ではありますが)。6 バイト文字の場合に使えるビット数は "1 + 6 + 6 + 6 + 6 + 6 = 31bit" となります。「あれ? UCS-4 は 32bit なので足りないんじゃ?」 と思われたかもしれませんが、実は UCS-4 の文字割り当て範囲は "0x00000000 ~ 0x7FFFFFFF" 迄の 31bit なのです。故に 6 バイト文字が最大のマルチバイト文字となります。
・
おさらい Part2
03/12 の表を変形してまとめてみると以下のようになります。
| Charset / Encoding | Range of 16bit (Legacy Unicode) | Range of 32bit | |
| Unicode (21bit 集合) | U+0000 ~ U+FFFF (BMP/Plane #0) | U+10000 ~ U+10FFFF (Plane #1 ~ #16) |
|
| UCS-4 (31bit 集合) | 0x00000000 ~ 0x0000FFFF (Group #0 Plane #0) |
0x00010000 ~ 0x7FFFFFFF (Group #0 Plane #1 ~ Group #127 Plane #255) |
|
| UCS-2 (16bit 集合) | 0x0000 ~ 0xFFFF | N/A | |
| UTF-32 (32bit を表現可能) |
Unicode | 1DWORD 文字 |
1DWORD 文字 |
| UCS-4 | |||
| UCS-2 | N/A | ||
| UTF-16 (21bit を表現可能) |
Unicode | 1WORD 文字 |
2WORD 文字 (サロゲートペア) ※ UCS-4 のすべての範囲を表わす事はできない。 |
| UCS-4 | |||
| UCS-2 | N/A | ||
| UTF-8 (31bit を表現可能) |
Unicode | 1byte 文字~ 3byte 文字 | 4byte 文字 |
| UCS-4 | 4byte 文字~ 6byte 文字 |
||
| UCS-2 | N/A | ||
UTF は Unicode または UCS からの符号化方式 (エンコーディング)なので、上の表ではそれぞれ 3 パターンずつ存在します。
・
UCS って?
UCS の正式名称は "Universal Multiple-Octet Coded Character Set" であり、元々は文字集合ではなく "ISO / IEC 10646" という文字集合のための文字符号化方式でした。これまで UCS-2 を WORD、UCS-4 を DWORD と表現してきましたが、正確には byte / WORD / DWORD のいずれでも管理されていません。
本来の UCS は "ISO/IEC 10646 を符号化し、Group (群) / Plane (面) / Row (区) / Cell (点) をオクテットで分割して管理する" というものでした (故に UCS の数字はバイトではなくオクテットの事を指します)。UCS-2 は第 0 群第 0 面しか使わない...つまり区点のみの符号化文字集合で、UCS-4 は群面区点を使う符号化文字集合です。この概念は Unicode にもあり、Unicode では "Plane (面) / Row(区) / Cell(点)" となっています。但し、UCS-4 には Group (群) があり、さらに Plane (面) も 0 ~ 255 の全 256 面であるのに対し、Unicode には 0 ~ 16 の全 17 面しかありません。
現在の UCS は本来の UCS に "Unicode を押し込んだもの" なので、Unicode のサブセット (UCS-2) / スーパーセット (UCS-4: 但し実際に文字が割り当てられている範囲は Unicode と同じ) であり、それ以上でもそれ以下でもありません。Unicode 互換なので文字符号化方式 (文字エンコーディング)ではなく、あくまでも "文字集合" です。
・
Unicode 化と Win9x
Delphi の Unicode 化を推し進めるにあたって最大の弊害は Win9x の切り捨てです。
「Win9x にも W 系の API があったハズだろ? Win9x 切り捨てるなんてどうにかしている」という声があるかもしれませんが、それはWin9x で W 系 API を使った事のない人間の言う事です。Win9x で Unicode を扱える...つまり、A 系と W 系の API 両方が正しく動作するAPI というのはたったこれだけしかありません。
経験則で言えば、Win9x での W 系 API には 3 種類あるような気がします。
Win9x の切り捨てを行えば、QC#58386 のような問題は簡単に回避できます。他の多くの文字コードの問題も回避できます。古くから Windows を触ってきたヒトは Windows 98 / Me 等で "IE の追加サポート" で "~言語" とかいうのをインストールした事があるかもしれません。または XP 等で "追加の言語" をインストールした事があるかもしれませんね。端的に言えば、あれらは "コードページエンコーダ / デコーダとフォントの詰め合わせ" です。適切に組み込まれていれば、MutiByteToWideChar() / WideCharToMultiByte() API を使い、Unicode (UTF-16) を介して相互にコンバートする事も可能です (日本語 <-> Unicode <-> 日本語すらも...日本語のコードページは CP932 だけじゃありませんし)。以前 Tiburón の話で 「暗黙的変換は、Windows の機能を使う限りはサロゲートペアに関して心配する必要はないと思います」 と書いたのはこれが根拠です。
逆に Win9x が (完全ではないにしろ) 考慮されている現行の Delphi では、GUI (VCL) を除いたとしても 完全な Unicode 化はどうあがいても無理な訳で、散々 Unicode 話をしておきながら、QC#58386 に噛み付かないのは、その点を理解しているからです(MultiByteToWideChar() / WideCharToMultiByte() で代用できる訳ですし)。ここまでのトピックを読んだ方なら、02/24 の雑談にある 「Delphi 7 / 2007 / Tiburón ベース最新版と Delphi を使い分けた方がいいかも?」 という意見に賛同頂けるかもしれませんね。動作環境に Win9x を含めたいのなら"CodeGear がサポート中の最新版 Delphi"である Delphi 2007 を入手し、サポート期間中にできるだけ品質向上を図る必要がある訳です (可能であれば、D7 の入手も)。
"単一バイナリで Win9x で動作し、かつ NT 系 OS では Unicode (UTF-16) も使える RAD 環境" なんてのは理想的ではありますが...いくらなんでも無茶というものでしょう。VCL を捨てるというのなら、或いは実現可能かもしれませんが...。Win9x と Unicode はトレードオフの関係にあります。
個人的には Delphi 2007 での Unicode には興味ありません。"ANSI 版" だと割り切って使っています。
こんな事を書いてると 「VC++ は~」 とか言いだすヒトがきっと居るでしょう。そりゃ 文字列をポインタで処理すりゃなんでもアリですよ。「んじゃ、BCB は~」と言いだすヒトがきっと居るでしょう。"VCL と AnsiString を捨てられるのなら" ね。RAD と汎用性もトレードオフの関係にあります。
・
矩形選択バグに固執する意味。
簡単に言えば 「お前ら (ASCII 圏のヒト)、Unicode もマルチバイトもちゃんと理解してないだろ?そんなんで大丈夫なのか Tiburón は?」 って事です。しつこい位に繰り返しますが、ASCII 圏のヒトは文字コードに疎いです。Windows 版で構わないので、Safariでこのページを閲覧してみて下さい。このページは UTF-8 ですが、上の方の記事にあった "丈の右上に点 なサロゲートペア" が見事に表示されていないと思います (ちなみに Mac OS X も内部表現は UTF-16 です)...Apple はユニコードコンソーシアムのフルメンバー(提唱したのは XEROX 社、Apple は主導的立場の一社)ですよ?コンソーシアム参加企業の製品でさえ、このザマなのですから本当に恐れ入りますよ。
Delphi のコードエディタは内部表現を UTF-8 で行っている事がハッキリしています。現行の Delphi は ANSI 版ですから、MBCS な国 (或いは地域) でしか矩形選択バグは起きないような気がするでしょうが、実は ISO-8859 のコードページを使っても起こります。ISO-8859 のコードページには 0x80 以降の文字を UTF-8 で言う 2 バイト文字に割り当てられているものがあります (キリル文字等)。つまり "半角の大きさで 2 バイト" の文字ですね。
こうなってくると"矩形選択バグに遭遇しない国や地域の方が少ない"事になります (Delphi ユーザの人口比ではないですよ)。
Unicode (UTF-8)で 3 バイト文字に収まる国はまだいい方です...矩形選択バグ程度で済みますから。しかし、このままでは (Delphi 2007 程度の実装では) 4 バイト文字を使う国ではまたもやハンディを負わされる訳です。アプリケーションの国際化?リッチコンテンツ? ASP 開発?ちゃんちゃらおかしいです。Tiburón では "Unicode 完全対応" と謳ってあります。これは "Tiburón に英語ローカライズ版は存在しても英語版というものは存在しない" 事を意味します。本当にあなた方 (ASCII 圏のヒト) はそれを理解しているのか?と。
現時点で FT は開始されていません (少なくとも日本では)。Tiburón-FT に参加した時に、私の懸念が杞憂に終わる事をただただ願うばかりです。
・
U+200B
Unicode で U+200B が示す文字は "ZERO WIDTH SPACE" です。UTF-8 で言えば "半角 0 文字分の 3 バイト文字" ですね...誰だよ、こんなの考えたバカは。Delphi 2007 の IDE でこの文字を入力すると、文字幅は半角 SP 扱いになります。仕様通りに実装するとコードエディタ上で
|
と記述されていても、空文字列なのか、U+200B が 1,000 文字あるのか区別が付きませんものね...これはこれで正解だと思います。もちろん、矩形選択すると変な事になりますけどね。
・
では問題。
ここに "が" という文字があります。この文字は UTF-8 で何バイトでしょうか?そう...日本語の普通の全角文字だから 3 バイト文字ですよね?
正解は 6 バイトです。「Unicode は 21bit で UTF-8 なら 4 バイト文字が最大じゃなかったのか?」 と仰る事でしょう。はい、その通りです。この文字は "3 バイト文字 + 3 バイト文字" で表現されているのですから、何も間違ってはいません。
実はこの文字、"か(U+304B)" と"゙(U+3099)" の 2 つが組み合わさっています。これが "結合文字列 (Combining Characters)" という奴です (以前、ちょっとだけ触れています)。"が" をメモ帳にコピペして、文字の右側にカーソルを置き、バックスペースキーを押すと "か" になります...面白いですね。
この文字 (列) を Delphi 2007 の IDE に入力すると、通常選択しただけでグチャグチャになります...誰だよ、こんなの考えたバカは。
ちなみに結合文字列はアクセント記号付きの文字を使う国でも使われます。"か (U+304B)" と "゙ (U+3099)" の結合文字列の他に "が (U+304C)" という 3 バイト文字もあります。結合文字列を単一の文字に変換する事を "合成 (Composition)"、逆に "合成文字 (Composite Character)" から複数の結合文字へ変換する事を "分解 (Decomposition)" と呼びます。Mac OS X では結合文字列と合成文字が存在する場合にはデフォルトで結合文字列が使われるようです。
・
えーと。
Tiburón ではソースファイルの文字エンコードが全世界共通で UTF-8 デフォルトになる訳で。「自分が使わない文字での不具合は知ったこっちゃない」 という理屈はもはや通じないのですよ...今度からは皆が同じ文字エンコーディングのソースをいじるのですから。
現時点に於いても、コードエディタの問題は、何も日本人だけが言ってる訳じゃありません。QC#59136 とか QC#56611 (ロシアの方のようです。キリル文字使いますからね。こないだ、ロシアの 100 万台の PC に CodeGear 製品がインストールされたのでしたよね?) とかありますよ?
それから...何度も言うように "矩形選択バグが直せないのなら、他の Unicode 関連の問題を解決できるとは思えない" のですよ。目に見えるので比較的解り易い...故にサンプルケースとして取り上げてるだけの事です。私が "矩形選択バグさえ直ればいい" という考えしか持っていないのだとしたら、長々と Unicode 話をする必要もなかったでしょう? ANSI 版 Delphi ではコードエディタだけの問題でしたが、Tiburón (ヒトによっては 2007 も) では Delphi 全体に関わる話になってしまうのですよ。
"fully Unicode-compatibule (ロードマップより)" が、大風呂敷で終わるか否かの瀬戸際なんですってば。
・
Delphi
[Codename: Delphi]
![[Delphi1_ATHENA.bmp]](Delphi/archives/splash/Delphi1/Delphi1_ATHENA.bmp) |
![[Delphi1.jpg]](Delphi/archives/splash/Delphi1/Extras/Delphi1.jpg) |
|
| アテナさん | ロゴ | アテナさん + ロゴ (リソースに含まれていません) |
・
Delphi 2.0
[Codename: Polaris]
![[Delphi2_ATHENA.bmp]](Delphi/archives/splash/Delphi2/Delphi2_ATHENA.bmp) |
![[Delphi2.jpg]](Delphi/archives/splash/Delphi2/Extras/Delphi2.jpg) |
|
| アテナさん | ロゴ | アテナさん + ロゴ (リソースに含まれていません) |
・
Delphi 3.0 / 3.1
[Codename: Ivory]
![[Delphi3_16.bmp]](Delphi/archives/splash/Delphi3/Delphi3_16.bmp) |
![[Delphi3_HIGH.jpg]](Delphi/archives/splash/Delphi3/Delphi3_HIGH.jpg) |
| ロゴ (16 色) | ロゴ |
・
Delphi 4
[Codename: Allegro]
![[Delphi4_HIGH.jpg]](Delphi/archives/splash/Delphi4/Delphi4_HIGH.jpg) |
![[Delphi4_FT3.jpg]](Delphi/archives/splash/Delphi4/Extras/Delphi4_FT3.jpg) |
![[Delphi4_RC2.jpg]](Delphi/archives/splash/Delphi4/Extras/Delphi4_RC2.jpg) |
| ロゴ | ロゴ (Field Test 3) (リソースに含まれていません) |
ロゴ (RC2) (リソースに含まれていません) |
・
Delphi 5
[Codename: Argus]
![[Delphi5_HIGH.jpg]](Delphi/archives/splash/Delphi5/Delphi5_HIGH.jpg) |
![[Delphi5_FT1.jpg]](Delphi/archives/splash/Delphi5/Extras/Delphi5_FT1.jpg) |
![[Delphi5_FT1_Launcher.jpg]](Delphi/archives/splash/Delphi5/Extras/Delphi5_FT1_Launcher.jpg) |
![[Delphi5_Borcon_FT4.jpg]](Delphi/archives/splash/Delphi5/Extras/Delphi5_Borcon_FT4.jpg) |
| ロゴ | ロゴ (Field Test 1) (リソースに含まれていません) |
ロゴ (Field Test 1 Launcher) (リソースに含まれていません) |
ロゴ (Field Test 4) (リソースに含まれていません) |
・
Delphi 6
[Codename: Iliad]
![[Delphi6_HIGH.jpg]](Delphi/archives/splash/Delphi6/Delphi6_HIGH.jpg) |
| ロゴ |
・
Delphi 7 / 7.1
[Codename: Aurora]
![[Delphi7_HIGH.jpg]](Delphi/archives/splash/Delphi7/Delphi7_HIGH.jpg) |
![[Delphi7_HIGH1.jpg]](Delphi/archives/splash/Delphi7/Delphi7_HIGH1.jpg) |
| ロゴ | ロゴ? |
・
Delphi 8
[Codename: Octane]
・
Delphi 2005
[Codename: Diamondback]
![[Delphi2005_HIGH.jpg]](Delphi/archives/splash/Delphi2005/Delphi2005_HIGH.jpg) |
| ロゴ |
・
Delphi 2006 (BDS 2006 / Turbo Delphi)
[Codename: Dexter]
![[Delphi2006_HIGH.jpg]](Delphi/archives/splash/Delphi2006/Delphi2006_HIGH.jpg) |
![[Delphi2006_16.bmp]](Delphi/archives/splash/Delphi2006/Delphi2006_16.bmp) |
![[Delphi2006_DELPHI.jpg]](Delphi/archives/splash/Delphi2006/Delphi2006_DELPHI.jpg) |
![[Delphi2006_TURBO.jpg]](Delphi/archives/splash/Delphi2006/Delphi2006_TURBO.jpg) |
| BDS ロゴ | BDS ロゴ (16 色) | Delphi ロゴ | Turbo ロゴ |
・
Delphi 2007
[Codename: Spacely]
![[Delphi2007_HIGH.jpg]](Delphi/archives/splash/Delphi2007/R1/Delphi2007_HIGH.jpg) |
![[Delphi2007_16.bmp]](Delphi/archives/splash/Delphi2007/R1/Delphi2007_16.bmp) |
![[Delphi2007_DELPHI.jpg]](Delphi/archives/splash/Delphi2007/R1/Delphi2007_DELPHI.jpg) |
![[Delphi2007_TURBO.jpg]](Delphi/archives/splash/Delphi2007/R1/Delphi2007_TURBO.jpg) |
| CRS ロゴ | BDS ロゴ (16 色) | Delphi ロゴ | Turbo ロゴ |
・
Delphi 2007 (R2)
[Codename: Spacely]
![[Delphi2007_HIGH_R2.jpg]](Delphi/archives/splash/Delphi2007/R2/Delphi2007_HIGH_R2.jpg) |
![[Delphi2007_16_R2.bmp]](Delphi/archives/splash/Delphi2007/R2/Delphi2007_16_R2.bmp) |
![[Delphi2007_DELPHI_R2.jpg]](Delphi/archives/splash/Delphi2007/R2/Delphi2007_DELPHI_R2.jpg) |
![[Delphi2007_TURBO_R2.jpg]](Delphi/archives/splash/Delphi2007/R2/Delphi2007_TURBO_R2.jpg) |
| CRS ロゴ | BDS ロゴ (16 色) | Delphi ロゴ | Turbo ロゴ |
※"(リソースに含まれていません)" と記載のあるもの以外は、すべて本来のリソースのままです。一切の改変 / コンバートを行っておりません。
※画像の著作権は Borland/CodeGear が保有しています。
※画像は縮小して表示されていますが、画像をクリックすると別ウィンドウ(タブ)で実寸表示できます。
※このサイトでの画像の公開に際して問題がない事を確認しています。
・
ボソッ。
↑ Powered by フサ。
・
Vista SP1
出ましたねー。RC2 はインストール済でしたが、早速インストール。所要時間はあちこちで書かれているように 1 時間が目安です。その間、何度か再起動しますので、何かの作業をしながら SP1 適用はやめておいた方がいいです。再起動は問答無用で行われます(保存する時間も与えてくれません)。SP1 を適用して退社する...というのも一つの手かもしれません。
SP1 適用前とで違う点は結構あるようですが、普通に使う分には exFAT とデフラグ程度でしょうか。巷で言われている "ファイルコピーの高速化" は RC2 から比べても確かに行われているようですが、XP からすると "元に戻っただけ" にしか感じないかもしれません。
機能拡張の含まれていた XP-SP2 とは違い、"HotFix の集合体 (Hotfix Rollup Package)" と考えた方がいいようです。4 月中旬からは Windows Update 経由で自動 (強制?) アップデート行われるようですが、問答無用の再起動の件を考えれば、事前に手動でアップデートを行った方がいいかもしれません。
追加の言語を入れてしまい、SP1 が当てられないで困っている方は、
|
を実行し (要は [ コントロールパネル | 地域と言語のオプション | キーボードと言語 ] の事です)、"英語、フランス語、ドイツ語、日本語、スペイン語" 以外の追加言語をすべて削除して下さい (多分、一つずつです...ToT)。それ以外の問題に関してはここを参照の事。
・
5000 万件の中の一人?わかるわけないよぉー。
元ネタは "Crazy for you (TMN)" から。"ねんきん特別便" が私のトコにも届きました。
名寄せの段階で 「これとこれは同じじゃない?」 ってアタリの付いたヒトにしか届いていないのでしょうから、ある意味当然と言えば当然なのでしょうね。消えていたのは最初に就職した会社とその次の会社の厚生年金分でした (途中に国民年金アリ)。すべての国民年金とその後の厚生年金は現在まで見事に日付が繋がっています (未納はないようです)。転職を何度もやったヒトは、皆さんこんな感じなのでしょうね...。
・
MBCSUtils
最低限のマトモな "マルチバイト ANSI 文字列処理 / 文字コード変換処理" を行うためのユニット。
例えば、MbcsLength() は必ず文字数を返すし、MwcsLength() も文字数を返す。MbcsCopy() や MwcsCopy() は文字インデックス指定が可能で、文字単位の部分文字列を返す。Mbcs~() に渡した変数が UTF8String の場合には Mbcs~(~, CP_UTF8) のようにコードページを指定してやれば UTF8 のまま文字列操作が可能となる。
"最低限" というのは、"Ansi ~" と名の付く関数をすべて網羅している訳ではないから。例えば AnsiPos() 等はサポートされていない。
これには理由がある。MBCSUtils の関数のうち、ANSI に係るものはコードページの指定が可能となっている。しかし、AnsiPos() は内部で文字列比較の API (CompareString) を呼んでいるため、そのままでは実装できない。何故なら、CompareString() はコードページを指定して文字列を比較するのではなく、ロケール指定で比較するからだ。前にも書いたと思うが、ロケールとコードページは相互変換が不可能なので、文字列比較を伴う関数は別枠で用意するしかない。
他にも、コードページの指定には制限がある。ラウンドトリップ変換 (可逆変換) は無理だが、AnsiString (Shift_JIS) -> WideString (UTF-16) -> AnsiString (JIS Code) のように、日本語<->日本語変換も可能ではある。しかし、この際には JIS Code が入った AnsiString に対して MbcsLength() 等は利かない。何故なら、JIS Code は 1 バイト文字と 2 バイト文字の切り替えに SI/SO を使うからだ。"ABC(SI)あいう(SO)DEF" という文字列に対してバイトインデックスや文字インデックスは意味のない物になる事は容易に想像が付く (同様の理由で UTF-7 にも使えない)。
GB18030 (CP54936) の問題もある。これは、GBK を拡張したもので 1 / 2 / 4 バイトで構成されるマルチバイト文字コードとなる。このコードページは Mbcs~ 系の関数で処理できない。実装しようと思えばできるのだが、UTF-8 同様、マルチバイト文字コードであっても A 系 API に直接渡せるものではないし、AnsiString (GB18030) -> WideString (UTF-16) -> AnsiString (GB18030) はロスレス変換になるのでサポートしていない (WideString に変換してから処理しろ、って事)。
GBK は Shift_JIS 同様、2 バイト文字の 1 バイト目 (0x81~0xFE) と 2 バイト目 (0x40~0xFE、0x7F は除外) が重複し、2 バイト目は 1 バイト文字の範囲と重複する。GB18030 の 4 バイト文字は GBK2 バイト文字の 2 バイト目の範囲にない 0x30~0x39 を使い、これを 2 つ組み合わせて 4 バイト文字としている (GB18030 は GBK の上位互換)。1 バイト目と 3 バイト目、2 バイト目と 4 バイト目が重複する上、1 バイト目と 3 バイト目は 2 バイト文字の 1 バイト目と、2 バイト目と 4 バイト目は 1 バイト文字の範囲と重複するため、部分文字列では文字の先頭バイトを特定するのが非常に困難になっている (部分文字列では WideString 変換して処理するのすら困難、という事)。
MBCSUtils の文字コード変換を使えば、AnsiString / UTF8String / WideString / UCS4String を相互に変換可能で、サロゲートペア (WideString) や 4 バイト文字 (UTF8String) にも対応する (QC#58386 の問題を回避可能)。但し、AnsiString はその理屈からしてロスレス変換ができない事がある (特に日本語^^;A)。UTF8String / WideString / UCS4String のベースとなっているのはすべて Unicode なので、ラウンドトリップ変換はもちろん可能 (D2007 の RTL ではラウンドトリップ変換不可。サロゲートペアが失われる)。
・
MBCSUtils の文字コード変換
"AnsiStringTo???String() / ???StringToAnsiString()" は恐らく "GetACP() / GetOEMCP() で取得できるコードページ + UTF-7 (CP_UTF7) / UTF-8 (CP_UTF8)" しか変換できないと思っておいた方がいい。
上で言ってる AnsiString (Shift_JIS) -> WideString (UTF-16) -> AnsiString (JIS Code) を行うには ConvertString() を使う必要があると思う。この際に文字列操作を伴なわず、コンバートだけでよいのなら、ConvertString() のみの一回で Shift_JIS <-> JIS Code のように直接変換が可能 (EUC-JP も)。
但し、ここで言う Shift_JIS / JIS Code / EUC-JP は、それぞれ CP932 / CP50222 / CP51932 の事であり、Windows 以外の Shift_JIS / JIS Code / EUC-JP からロスレス変換できると思ってはいけない。また、ConvertString() では UTF-16 (CP1200) / UTF-16BE (CP1201) / UTF-32 (CP12000) / UTF-32BE (CP12001) を恐らく使えない。.NET 専用のようだ...故に ConvertString() / ConvertStr() は AnsiChar / PAnsiChar しか許容しない。
追記: MBCSUtils の後継である "MECSUtils" がリリースされています。
| BACK | 古いのを読む | 新しいのを読む |