| 16 | 15 | 14 | 13 | 12 | 11 | 10 | 9 | 8 | 7 | 6 | 5 | 4 | 3 | 2 | 1 |
| サロゲート #1 (110110) | プレーン番号(Unicodeの上位 5bit)-1 | Unicodeの上位6bit目から 6bit | |||||||||||||
| 16 | 15 | 14 | 13 | 12 | 11 | 10 | 9 | 8 | 7 | 6 | 5 | 4 | 3 | 2 | 1 |
| サロゲート #2 (110111) | Unicodeの下位10bit | ||||||||||||||
| 8 | 7 | 6 | 5 | 4 | 3 | 2 | 1 |
| 0 | U+0000~U+007F(BMP) |
||||||
| 8 | 7 | 6 | 5 | 4 | 3 | 2 | 1 |
| 1 | 1 |
0 | U+0080~U+07FF(BMP) の上位5ビット分 | ||||
| 8 | 7 | 6 | 5 | 4 | 3 | 2 | 1 |
| 1 | 0 |
U+0080~U+07FF(BMP) の下位6ビット分 | |||||
| 8 | 7 | 6 | 5 | 4 | 3 | 2 | 1 |
| 1 | 1 |
1 | 0 |
U+0800~U+FFFF(BMP) の上位4ビット分 | |||
| 8 | 7 | 6 | 5 | 4 | 3 | 2 | 1 |
| 1 | 0 |
U+0800~U+FFFF(BMP) の上位5ビットから6ビット分 | |||||
| 8 | 7 | 6 | 5 | 4 | 3 | 2 | 1 |
| 1 | 0 |
U+0800~U+FFFF(BMP) の下位6ビット分 | |||||
| 8 | 7 | 6 | 5 | 4 | 3 | 2 | 1 |
| 1 | 1 |
1 | 1 |
0 |
U+10000~U+10FFFFの上位3ビット分 | ||
| 8 | 7 | 6 | 5 | 4 | 3 | 2 | 1 |
| 1 | 0 |
U+10000~U+10FFFFの上位4ビット目から6ビット分 | |||||
| 8 | 7 | 6 | 5 | 4 | 3 | 2 | 1 |
| 1 | 0 |
U+10000~U+10FFFFの上位10ビット目から6ビット分 | |||||
| 8 | 7 | 6 | 5 | 4 | 3 | 2 | 1 |
| 1 | 0 |
U+10000~U+10FFFFの下位6ビット分 | |||||
| Charset/Encoding |
Range of 16bit (Legacy Unicode) | Range of 32bit | |
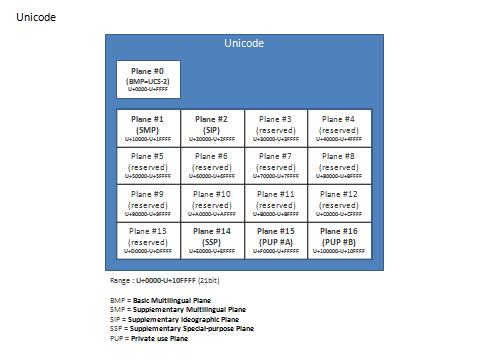
| Unicode (21bit集合) | U+0000~U+FFFF (BMP/Plane #0) | U+10000~U+10FFFF (Plane #1~Plane #16) |
|
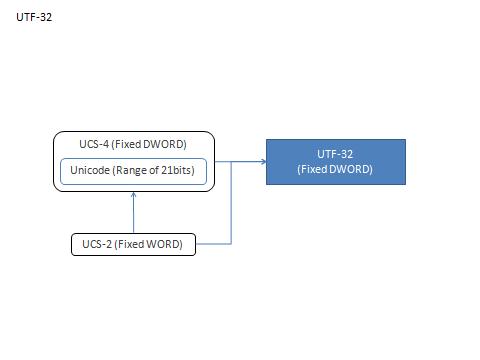
| UCS-4 (31bit集合) | 0x00000000~0x0000FFFF (Group #0 Plane #0) |
0x00010000~0x7FFFFFFF (Group #0 Plane #1~Group #127 Plane #255) |
|
| UCS-2 (16bit集合) | 0x0000~0xFFFF | N/A | |
| UTF-32 (32bitを表現可能) |
Unicode | 1DWORD文字 |
1DWORD文字 |
| UCS-4 | |||
| UCS-2 | N/A | ||
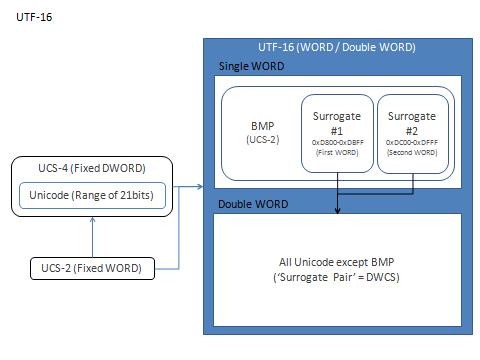
| UTF-16 (21bitを表現可能) |
Unicode | 1WORD文字 |
2WORD文字 (サロゲートペア) ※UCS-4のすべての範囲を表わす事はできない。 |
| UCS-4 | |||
| UCS-2 | N/A | ||
| UTF-8 (31bitを表現可能) |
Unicode | 1byte文字~3byte文字 | 4byte文字 |
| UCS-4 | 4byte文字~6byte文字 |
||
| UCS-2 | N/A | ||
| H | e | l | l | o | , | w | o | r | l | d | . | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| あ | い | う | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
|
|
|
| BACK |